
traceroute原理(以及wireshark对traceroute报文的分析)
Traceroute 就像ping命令一样,可以帮助我们排查网络故障,但ping 有时候会有局限性,例如下面192.168.1.1 ping 不通192.168.3.1,但我们不知道问题是否在 H1-R1、R1-R2、R2-R3 或 R3-S1 之间。假设你知道有多少台路由器以及每台设备的IP 地址,那么你可以逐跳去ping测试,但对于一个大型网络在你不知道中间设备以及流量路径的情况下,你可能会需要使用traceroute来快速判断问题点在哪。

那么,traceroute 是如何工作的呢?
Traceroute 使用 IP 数据包头中的 TTL(生存时间)字段。通常TTL 用于在存在路由环路时能够防止数据包永远无休止的转发下去,每当路由器转发 IP 数据包时,TTL 减 1,当TTL 为零时,IP 数据包将被丢弃。
traceroute是如何工作的请看下面案例,假设从 (192.168.1.1) 向 S1 (192.168.3.1) 发送跟踪,H1 发送的第一个 IP 数据包的 TTL 为 1;

当 R1 收到此 IP 数据包时,它想要将其转发给 R2,但它必须将 TTL 从 1 减少到 0,结果IP 数据包将被丢弃,R1 将使用TTL 超出消息响应 H1,H现在将发送第二个包其TTL为 2;

R1 会将 TTL 从 2 减少到 1,转发它到R2,现在 R2 必须丢弃它,R2 将回复一个 TTL超时消息。H1现在将发送另一个 TTL 为 3 的 IP 数据包;

R1将TTL从3减少到 2,R2将其从 2 减少到1,R3将不得不丢它,R3将TTL 超时消息发送给 H1,紧接着H1 将发送的最后一个 IP 数据包其 TTL 为 4;

每个路由器都会将 TTL 减 1,另一端的服务器S1将收到一个 TTL 为 1 的 IP 数据包,并以ICMP 协议回复 H1。现在我们知道目的地是可达的,并且了解了路径上所经过的设备。
traceroute发送的每个 IP 数据包都称为一个probe。Traceroute 可用于 ICMP、UDP 和 TCP,具体取决于其操作系统类型。
Traceroute的wireshark报文分析:
上面有两台主机,H1 是 Windows 计算机(192.168.1.1),H2 是Linux 计算机(192.168.1.2)
如下为windows系统的traceroute:
C:\Users\vmware>tracert 192.168.3.1
Tracing route to 192.168.3.1 over a maximum of 30 hops
1 1 ms 1 ms <1 ms 192.168.1.254
2 1 ms 1 ms 1 ms 192.168.12.2
3 1 ms 1 ms 1 ms 192.168.23.3
4 1 ms <1 ms <1 ms 192.168.3.1
Trace complete.
通过上面的输出我们可以看到所有的路由器,对于每一跳,traceroute 将发送三个 IP 数据包,这样是为了获得每跳的往返时间的平均值,让我们看看 Wireshark 中的 IP 数据包是什么样的,这是第一个包;
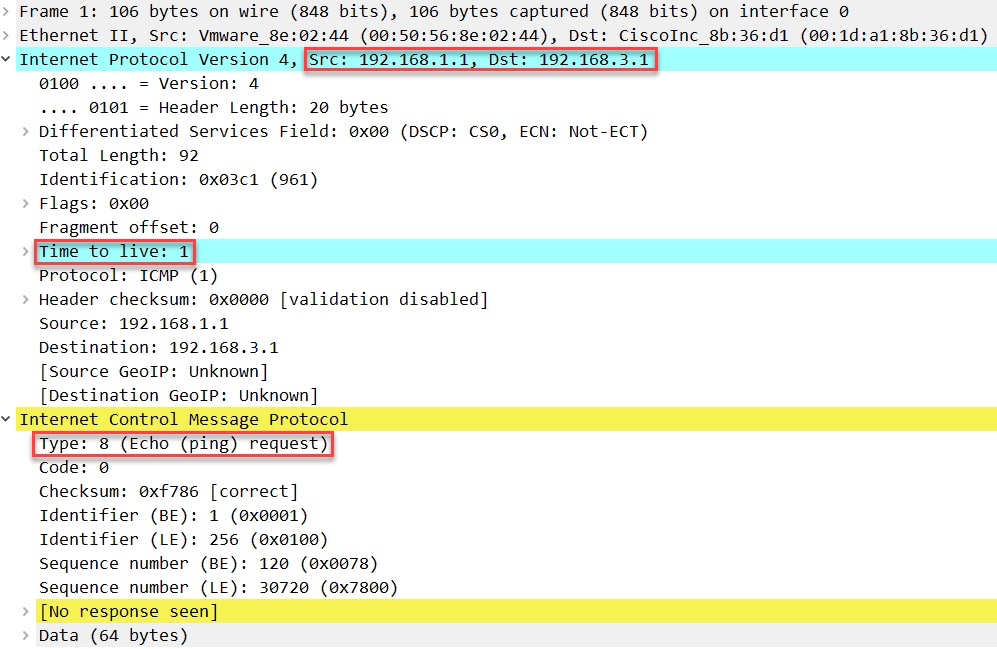
上面我们看到第一个 TTL 为 1 的 IP 数据包,我们可以看到这是一个ICMP请求,当 R1 收到这个 IP 数据包时,它会这样回应:

上面我们看到 R1 用 TTL 超时消息响应 H1,在抓包文件中,你会看到上面的两个数据包发了三次。我们看下一个IP包:
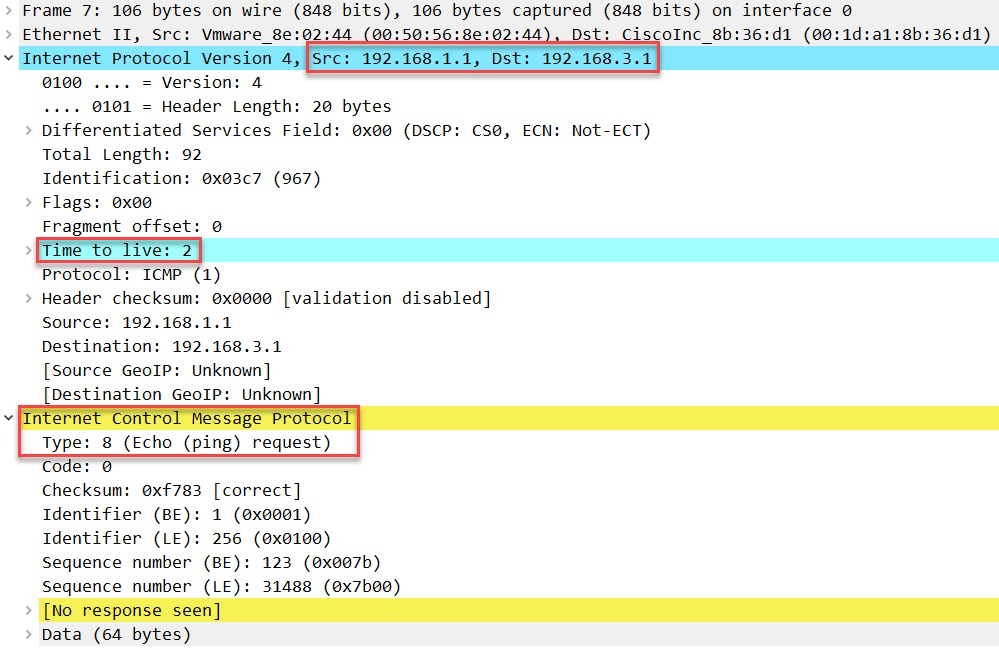
这一次TTL 值为2,将发往R2;

第三个包TTL 值为3;
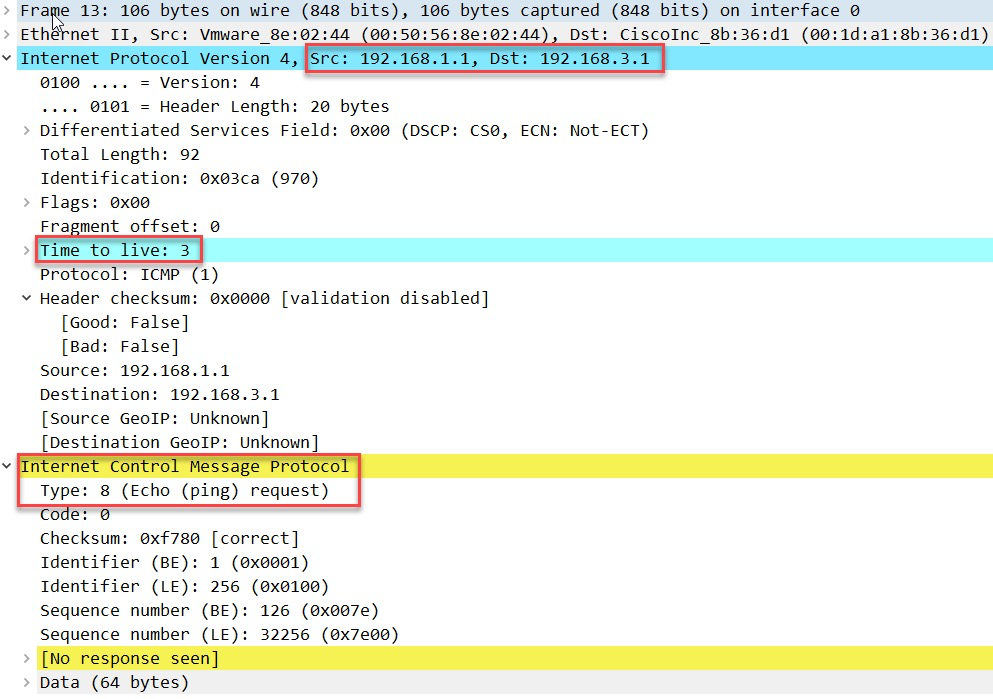
R3 回复TTL 超时消息
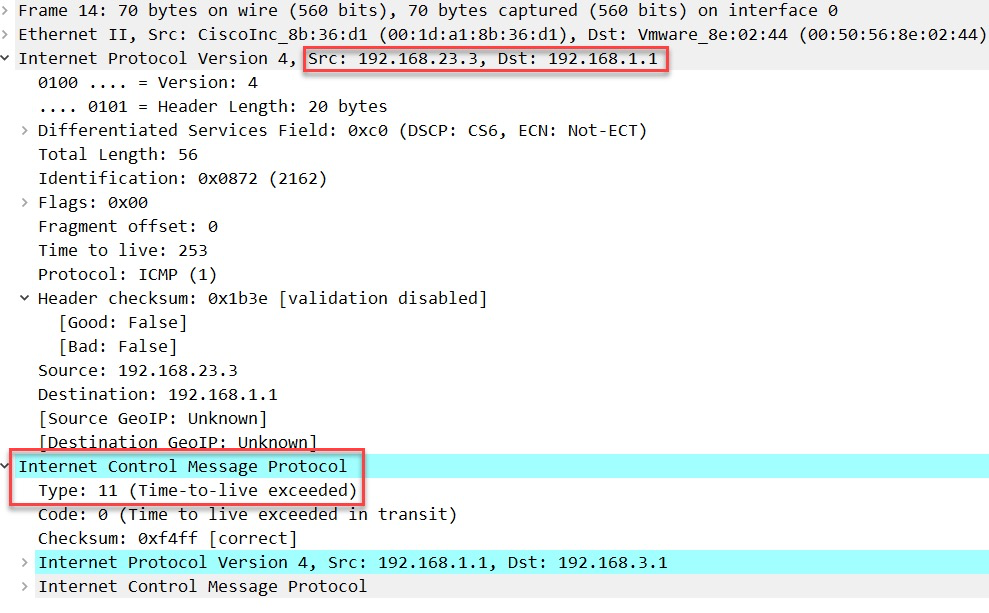
最后,H1 将发送一个TTL值为4 的IP 数据包;

这个最后一个包发往S1,并可以看到ICMP reply报文:
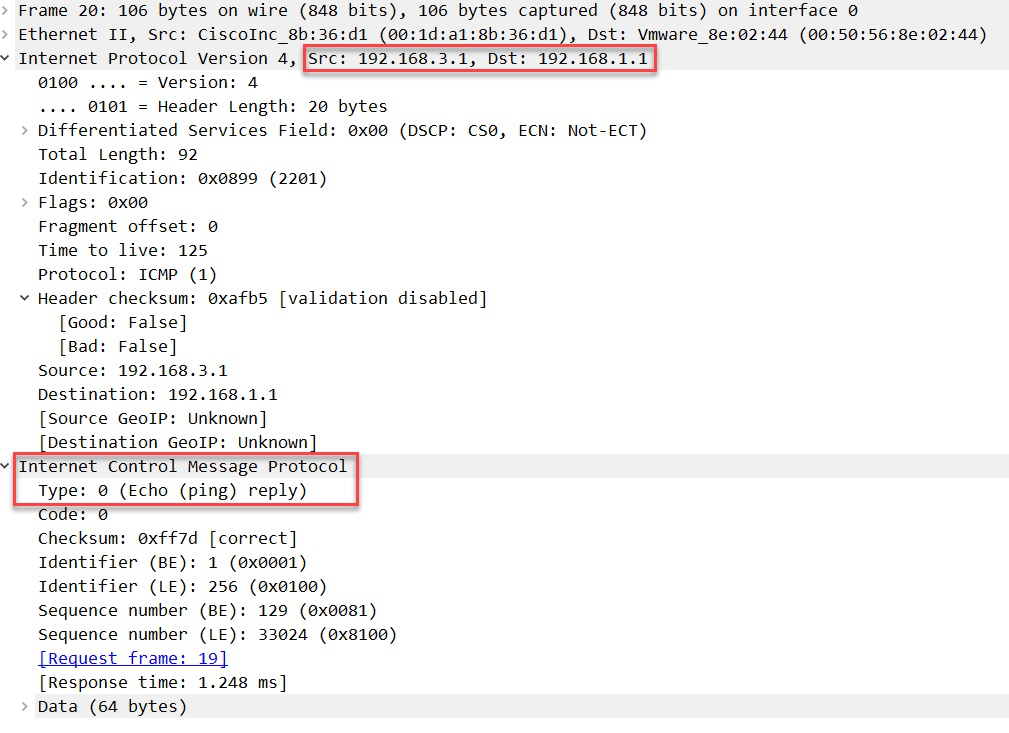
这就是 traceroute 在 Windows 上的工作方式,下面看traceroute在Linux上面的工作方式。
Linux 上的 traceroute 命令的工作方式与 Windows 类似。一个重要的区别是它不使用 ICMP,而是使用 UDP。它还允许您指定要发送的 IP 数据包(探测)的数量。为了便于观看wireshak,仅配置发送一次探测;
$ traceroute -N 1 -q 1 192.168.3.1
traceroute to 192.168.3.1 (192.168.3.1), 30 hops max, 60 byte packets
1 192.168.1.254 (192.168.1.254) 1.202 ms
2 192.168.12.2 (192.168.12.2) 1.122 ms
3 192.168.23.3 (192.168.23.3) 1.192 ms
4 192.168.3.1 (192.168.3.1) 1.886 ms
下面是这个 traceroute 在 Wireshark 中的样子

上面我们可以看到 H2 正在发送 UDP 数据包而不是 ICMP 请求,如下是第一个报文:
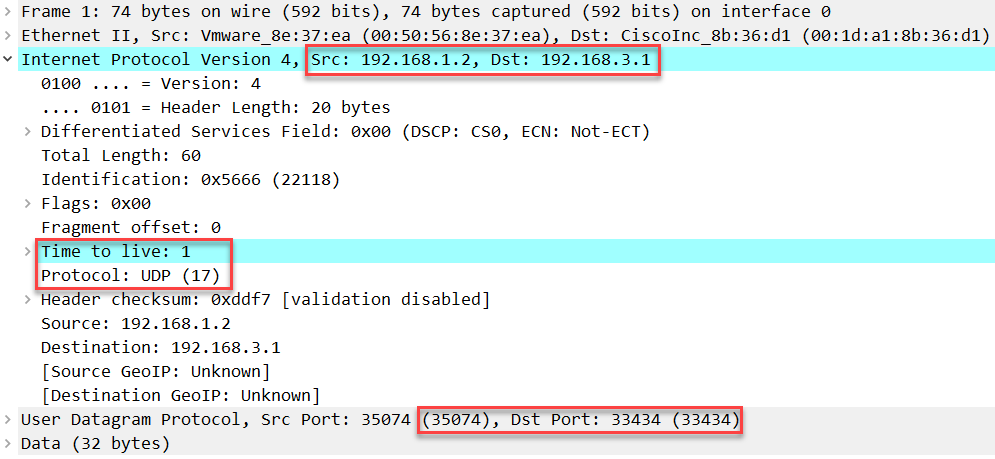
上面我们看到 H2 发送的第一个 TTL 为 1 的 IP 数据包,我们看到它使用的是UDP,目的端口号是33434,R1回复如下信息:
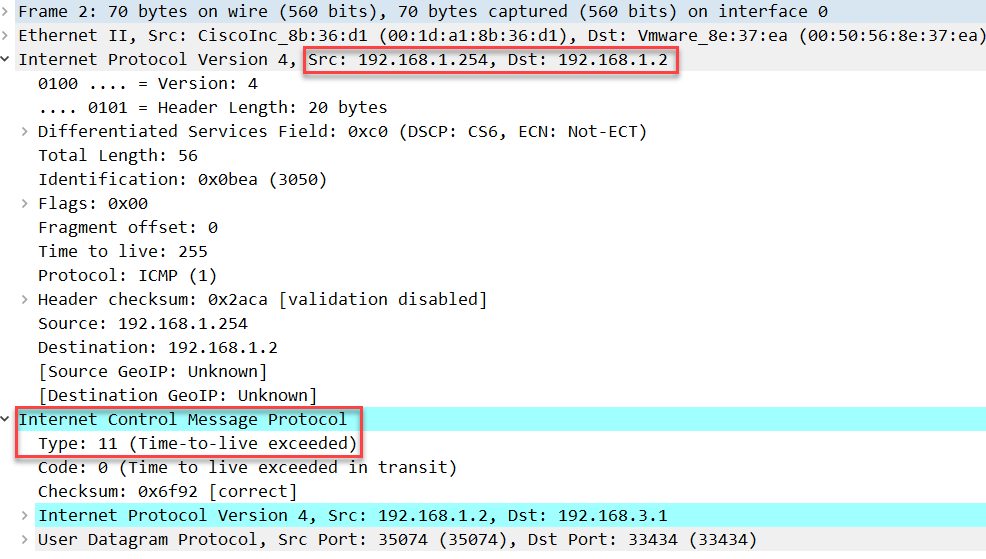
由于 TTL 为零,R1 将其丢弃并回复 TTL 超时消息,如下第二个TTL为2的数据包;

上面的数据包与第一个相同,只是可以看到目标端口号从 33434 增加到 33435,R2 将会继续丢弃:
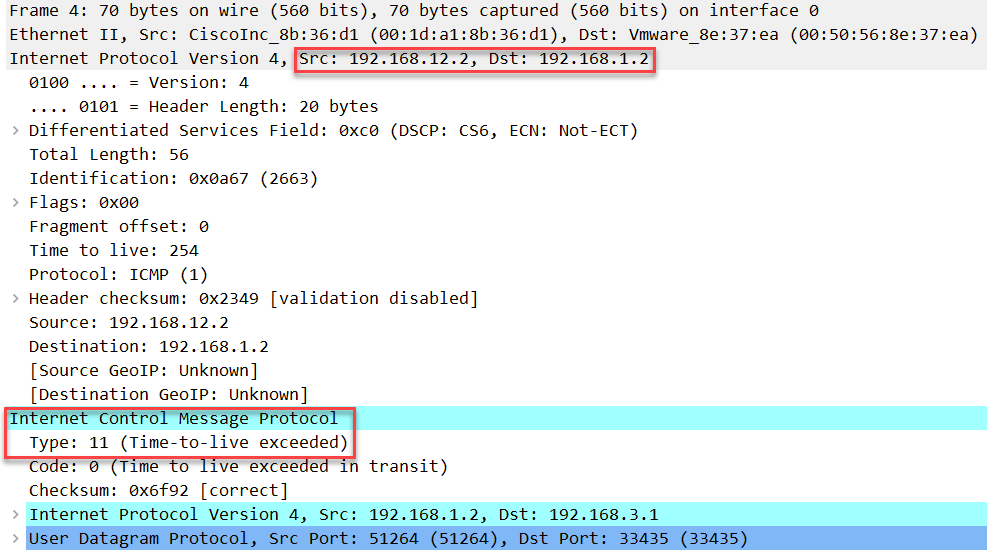
TTL 为 3 的数据包:
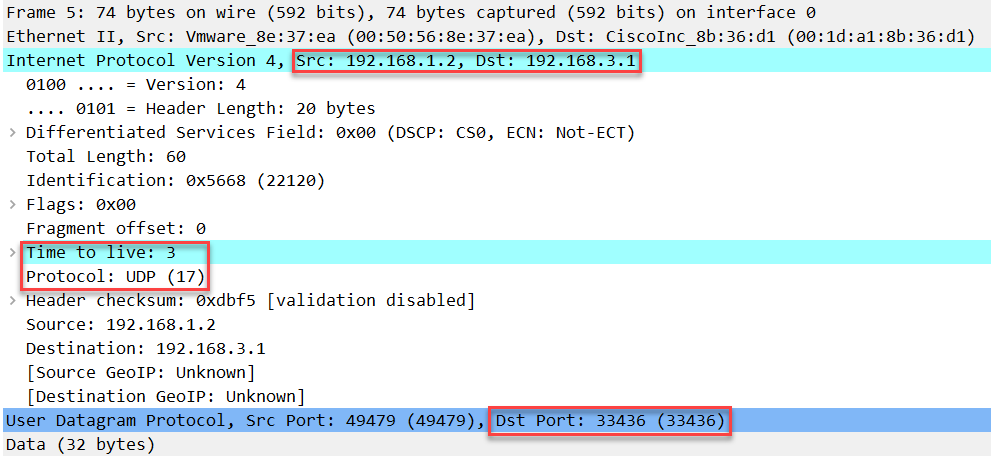
上面你可以看到目标端口号从 33435 增加到 33436,R3 会继续丢弃此报文:
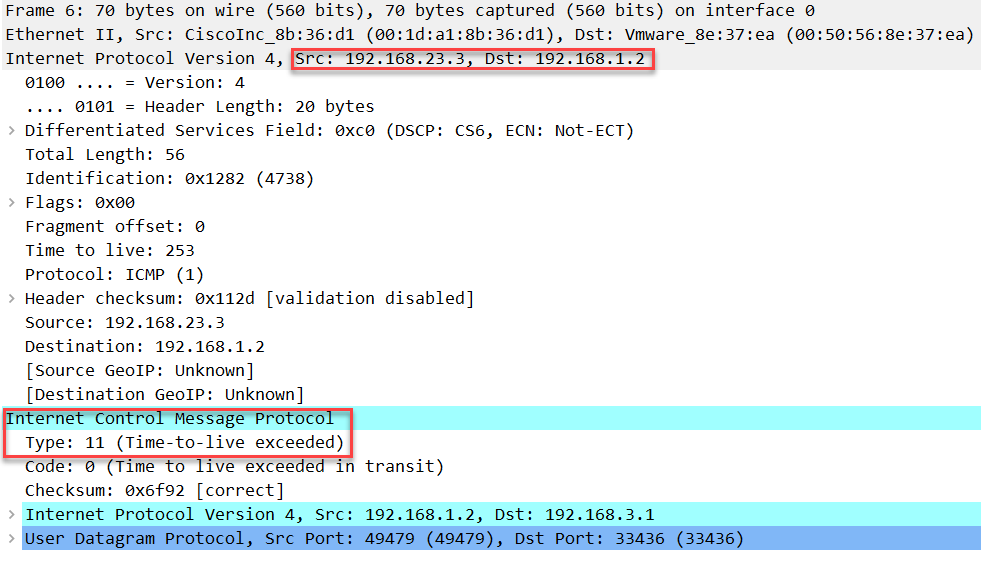
最后一个数据包的 TTL 为 4,目的端口号为 33437:
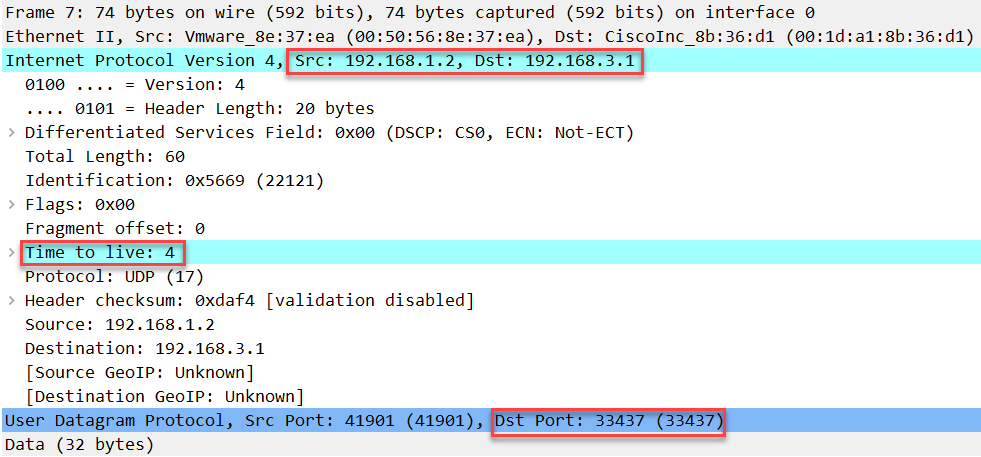
这个包将一直传送到S1,由于 S1 没有监听这些 UDP 端口号中的任何一个,它会回复目标/端口不可达:
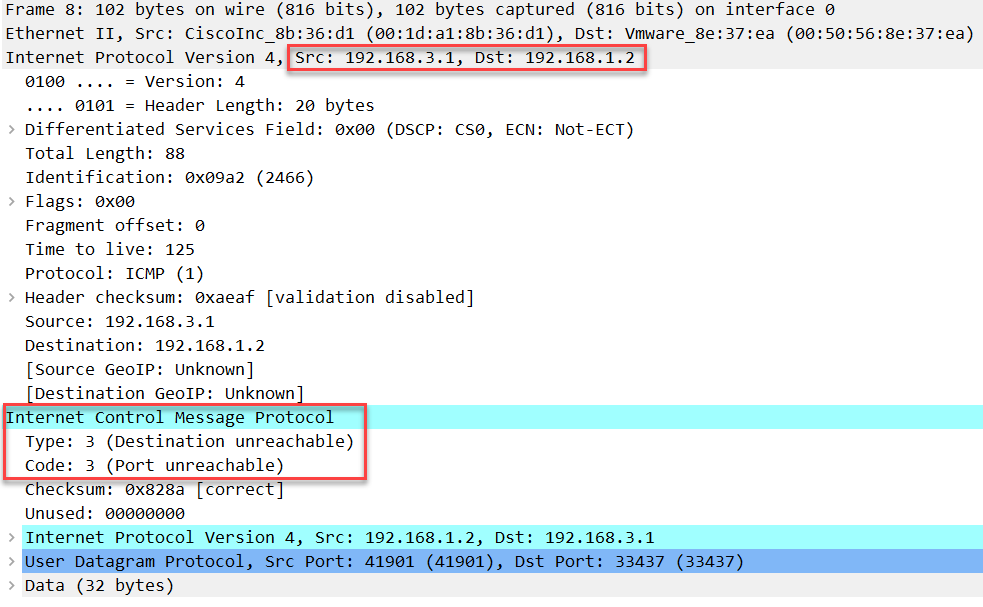
这里告诉 H2 我们已经到达目的地了
思科IOS
我们还可以在 Cisco IOS 上使用 traceroute 命令。与 Linux 一样,Cisco 使用 UDP 进行跟踪路由。从 R1 到 S1 进行跟踪,使用单个探针:
R1#traceroute 192.168.3.1 probe 1
Type escape sequence to abort.
Tracing the route to 192.168.3.1
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 0 msec
2 192.168.23.3 4 msec
3 192.168.3.1 0 msec
在上面我们看到这条轨迹到达了目的地。
Cisco IOS 上的跟踪路由可能非常慢,这是因为它将尝试对每个 IP 地址进行 DNS 查找,为了使其更快,请确保可以解析这些查找或使用no ip domain-lookup 命令禁用 DNS 查找。
以下是 Wireshark 报文:

这个抓图和刚刚看到的Linux抓图是一样的,所以不再添加更多的截图了。
故障排除案例:
在这个例子中我只需要三个路由器:

目的地不可达
让我们从一个无法到达的目的地开始,在 R3 上添加一个具有 IP 地址的环回口:
R3(config)#interface loopback 0
R3(config-if)#ip address 3.3.3.3 255.255.255.255
目前,路由器都不知道如何到达 3.3.3.3。让我们先看看 traceroute 输出是什么样的:
R1#traceroute 3.3.3.3
Type escape sequence to abort.
Tracing the route to 3.3.3.3
VRF info: (vrf in name/id, vrf out name/id)
1 * * *
2 * * *
3 * * *
上面我们看到没有一个探测器可到达目的地,然后我们在 R1 上添加一条静态路由,以便此流量至少到达 R2:
R1(config)#ip route 3.3.3.3 255.255.255.255 192.168.12.2
并执行另一个跟踪路由:
R1#traceroute 3.3.3.3
Type escape sequence to abort.
Tracing the route to 3.3.3.3
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 4 msec 0 msec 4 msec
2 192.168.12.2 !H * !H
现在我们可以看到 R1 能够转发它,R2 响应它不可达,然后我们在 R2 上添加静态路由:
R2(config)#ip route 3.3.3.3 255.255.255.255 192.168.23.3
再尝试一个跟踪:
R1#traceroute 3.3.3.3
Type escape sequence to abort.
Tracing the route to 3.3.3.3
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 0 msec 4 msec 0 msec
2 192.168.23.3 4 msec * 0 msec
现在我们可以到达目的地了。
源不可达
我们可以使用 traceroute 来确定我们是否可以到达某个目的地,但也可以使用它来检查其他路由器是否知道您的来源,这次在R1 上面添加一个环回口:
R1(config)#interface loopback 0
R1(config-if)#ip address 1.1.1.1 255.255.255.255
我现在将使用 1.1.1.1 作为我们的源对 192.168.3.1 进行跟踪路由,我们知道 192.168.3.1 是可达的,因为我们之前尝试过,让我们来看看:
R1#traceroute 192.168.3.1 source loopback 0
Type escape sequence to abort.
Tracing the route to 192.168.3.1
VRF info: (vrf in name/id, vrf out name/id)
1 * * *
2 * * *
3 * * *
此跟踪失败,没有人知道如何到达 1.1.1.1。让我们在 R2 上添加一条静态路由:
R2(config)#ip route 1.1.1.1 255.255.255.255 192.168.12.1
R2 现在知道如何达到 1.1.1.1。让我们再次尝试该 traceroute:
R1#traceroute 192.168.3.1 source loopback 0
Type escape sequence to abort.
Tracing the route to 192.168.3.1
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 0 msec 4 msec 0 msec
2 * * *
3 * * *
R2 做了响应,这说明问题不在 R1 和 R2 之间,而是在更远的地方。让我们添加最后一个静态路由:
R3(config)#ip route 1.1.1.1 255.255.255.255 192.168.23.2
R3 现在也知道如何到达 1.1.1.1,让我们试试那个跟踪:
R1#traceroute 192.168.3.1 source loopback 0
Type escape sequence to abort.
Tracing the route to 192.168.3.1
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 0 msec 4 msec 0 msec
2 192.168.23.3 4 msec 0 msec 0 msec
3 192.168.3.1 0 msec 0 msec 4 msec
现在成功完成。
结论
通过此文档相信您已经了解了traceroute 如何使用 IP 数据包中的 TTL(生存时间)字段向目标发送探测,从而允许我们发现从源到目标的路径,您还看到了 Windows 如何使用 ICMP 和 Linux 如何使用 UDP 进行跟踪路由,我们还研究了如何使用 traceroute 对源和/或目标未知的网络可达性问题进行故障排除,如果您在某些路由器的跟踪中看到一些星号(超时),则也可能该路由器(或防火墙)可能配置了访问列表,并配置为不响应任何 TTL 过期消息。
